Generative Data Augmentation Challenge: Synthesis of Room Acoustics for Speaker Distance Estimation
ICASSP 2025: Generative Data Augmentation Challenge
Jackie Lin¹, Georg Götz², Hermes Sampedro Llopis², Haukur Hafsteinsson², Steinar Guðjónsson², Daniel Gert Nielsen²,
Finnur Pind², Paris Smaragdis¹, Dinesh Manocha³, John Hershey⁴, Trausti Kristjansson⁵, and Minje Kim¹,⁵
¹University of Illinois at Urbana-Champaign, ²Treble Technologies, ³University of Maryland,
⁴Google Research, ⁵Amazon Lab126
ABSTRACT
This paper describes the synthesis of the room acoustics challenge as a part of the generative data augmentation workshop at ICASSP 2025. The challenge defines a unique generative task that is designed to improve the quantity and diversity of the room impulse responses dataset so that it can be used for spatially sensitive downstream tasks: speaker distance estimation. The challenge identifies the technical difficulty in measuring or simulating many rooms’ acoustic characteristics precisely. As a solution, it proposes generative data augmentation as an alternative that can potentially be used to improve various downstream tasks.
The challenge website, dataset, and evaluation code are available at https://sites.google.com/view/genda2025.
Index Terms—Room acoustics, spatial audio, room impulse response, speaker distance estimation
1. Introduction
In recent years, the room acoustics and spatial audio research field has seen a surge of research motivated by new technology such as augmented and virtual reality (AR/VR), deep learning, and parallel computing. The technology is largely based on precise characterization of the room acoustics by considering various factors, such as the shape of the room, furniture layout, positions and directionality of the sources and receivers, the material of the walls, and more. One of the most effective, yet exhaustive characterizations of a room’s acoustics is a dense set of room impulse responses (RIR) recorded at fine enough source-receiver positions in the room. Indeed, the explosion of learning-based approaches for old and new room acoustics tasks has increased the demand for such RIR data. However, when the RIR datasets used to train spatial audio systems are not diverse enough, these systems often struggle to generalize to new, unfamiliar rooms. This leads to poor user experiences or inaccurate results. Furthermore, gathering a diverse and large set of RIRs is in fact quite difficult; the process and equipment for measuring high-quality RIRs are costly and technical, and traditional room acoustics simulation methods suffer strong trade-offs between accuracy and computational cost. Over the years, many dataset papers have attempted to fill gaps in the public dataset ecosystem [1]–[7], demonstrating the demand for and the challenge of obtaining quality room acoustics data. In this challenge, we recognize the inherent value of generative AI models for data augmentation. As demonstrated in other domain areas such as computer vision [8]–[10], speech synthesis [11], [12],and natural language understanding [13], a well-designed generative model can help augment existing datasets that are often limited in quantity and diversity. The proposed challenge promotes research in generating RIR datasets. The synthesized RIRs can be directly used for various applications such as room auralization and spatial audio rendering, but this challenge focuses on using them to augment existing RIR datasets to train a better machine learning (ML) model. To this end, we propose to use the augmented dataset to improve the speaker distance estimation (SDE) task, where the ML model predicts the physical distance between a speech source and the receiver based only on the single-channel reverberant observation. The challenge asks participants to develop a generative model to reconstruct the RIRs of several rooms, given only a limited amount of information about the rooms, such as only a few RIR signals and basic shapes of the rooms. Then, the organizers compare participants’ reconstructed RIRs with the held-out ground-truth RIRs to assess their quality. In addition, participants are asked to train SDE systems from a reverberant speech dataset they construct based on the generated RIRs. Their distance estimation performance will be evaluated on the hidden test signals, whose actual distances are kept from the participants. The overall pipeline of the generative data augmentation used for SDE is shown in Fig. 1.
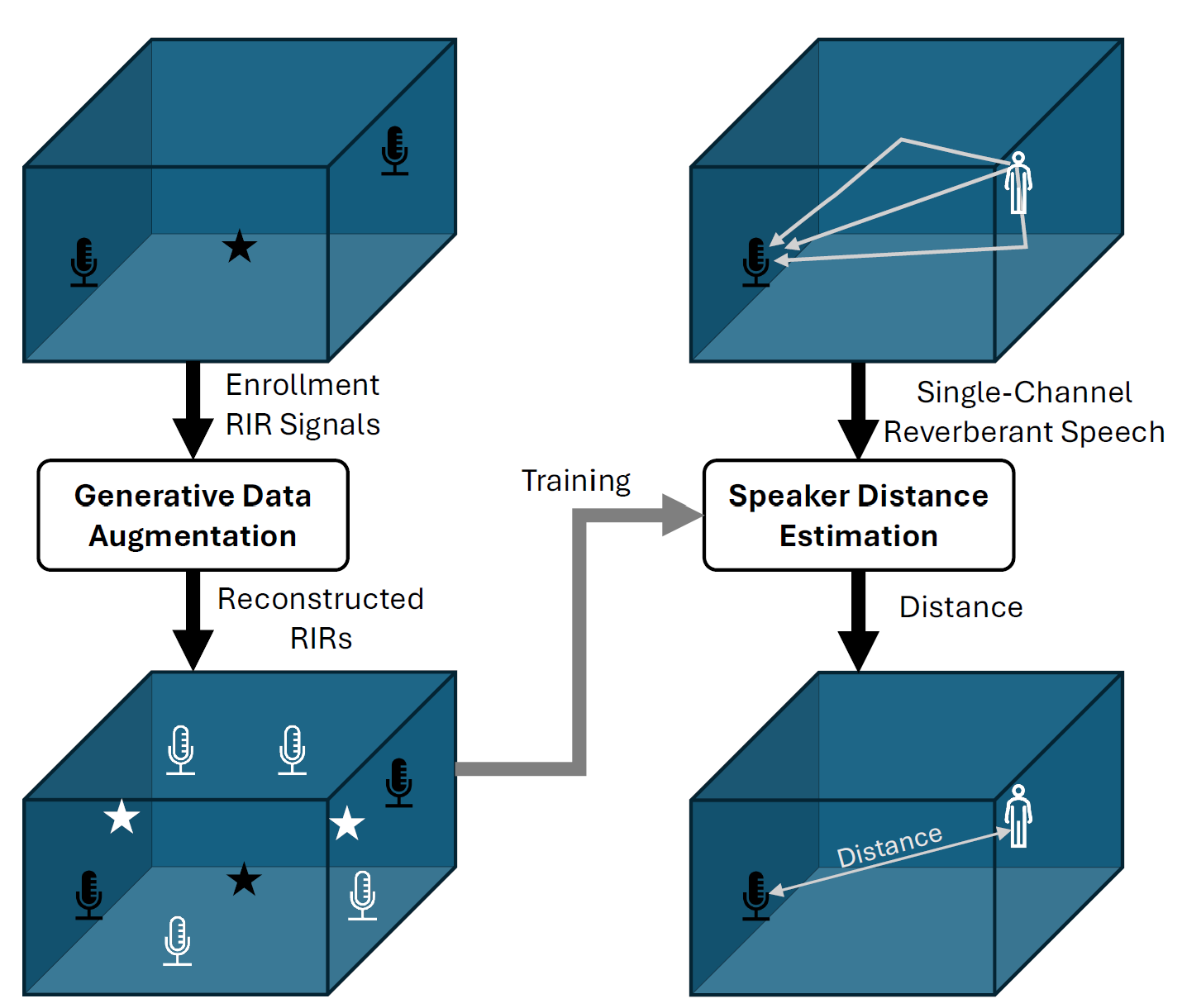
Figure 1: Overview of the generative data augmentation pipeline.
In this paper, we describe the challenge, datasets, evaluation methods, and baseline systems. The enrollment RIRs, 3D models of the rooms, test room-source-receiver locations, reverberant speech test set, evaluation metric functions, and trained downstream SDE models are provided in this link: https://sites.google.com/view/genda2025
2. Challenge Description
A. Basic Challenge Description
The challenge tasks participants to generate a room's acoustics in the form of RIRs with only a limited amount of information about the room. The assumption is that the acoustical information of the room is difficult to measure or acquire for a normal user, while knowing the room acoustics is very important for end-user applications, such as AR/VR. Hence, a data augmentation method can be useful for estimating a specific room's acoustic information, which fleshes out an elementary set of available information that a non-technical user can easily provide. For example, the user can provide a few RIRs at a handful of locations to help improve the performance of a system. In addition, images of the room can indirectly inform a system of the room's geometry and furniture layouts. We expect that a successful generative model can figure out RIRs from various locations of the room to the degree that is useful enough for other downstream tasks.
To simulate this use case, participants are asked to generate the RIRs at unseen source-receiver locations in ten rooms given a set of enrollment RIRs and their source-receiver locations from those rooms. The organizers will also provide other information for advanced generation methods, such as the 3D model of the room shape, furniture layouts, and Ambisonic RIRs.
B. Evaluation of the Participating Systems and the Downstream Task
Participants are asked to submit five RIRs from each of the ten rooms for a total of 50 RIR signals from the designated sourcereceiver locations. Their submission is an estimate of the held-out ground-truth RIRs. A straightforward method to assess the quality of the participating generative system is to directly compare the submission with the corresponding ground truth by using various objective metrics as listed in Sec. 4. That being said, the challenge also validates the generated RIRs by examining their usefulness in the downstream task, where correct room simulation is critical for its performance. We choose the singlechannel speaker distance estimation task because it is a challenging problem, relying only on the spectral and temporal characteristics of the observed signal in the single-channel scenario. A successful SDE system needs to be trained on various source-microphone location pairs in many different realistic rooms, so it generalizes well to unseen rooms. To minimize participants’ effort in developing the SDE system from scratch, the organizers repurpose a state-of-the-art SDE model and provide a checkpoint publicly as the baseline, described in Sec V. The organizer-provided SDE model also standardizes the evaluation process so that the comparison of the submissions is affected not by the choice of SDE model architecture, but by the quality of their data augmentation performance. Building off the provided SDE baseline model, but without changing its architecture, we encourage participants to improve the SDE prediction accuracy by fine-tuning the model on generated data. In theory, a model that generalizes well to any test environment should just work fine for our test signals, but we expect the model to be fine-tuned to work well for the rooms provided in the challenge. The fine-tuning can be done by creating many virtual speakers at different locations in the room, whose reverberant speech utterances recorded at another virtual microphone location serve as input to the SDE system. As the geometry of the virtual speakers and receivers is known, the model can be trained with the suitable target distance that makes sense between the virtual sources and microphones. The challenging part must be whether the generated RIR filter is realistic enough for the model to learn the room acoustics correctly. To evaluate these systems, participants are provided with a test set of reverberant speech utterances from undisclosed speaker locations from this challenge’s dataset. Participants will run their SDE system and submit the estimated distances, which are then compared with the ground truth to calculate the error. In the additional bonus track, the organizers also welcome new model architectures for SDE, which participants can utilize to explore more structural variations.
Table 1: Overview of the dataset.
| Room ID | Description | Measured | Simulated |
|---|---|---|---|
| Room_0 | Control - Treble room | ✓ | ✓ |
| Room_1 | Bathroom 1 | ✓ | |
| Room_2 | Bathroom 2 | ✓ | |
| Room_3 | Bedroom 1 | ✓ | |
| Room_4 | Bedroom 2 | ✓ | |
| Room_5 | Living room with hallway 1 | ✓ | |
| Room_6 | Living room with hallway 2 | ✓ | |
| Room_7 | Living room 1 | ✓ | |
| Room_8 | Living room 2 | ✓ | |
| Room_9 | Meeting room 1 | ✓ | |
| Room_10 | Meeting room 2 | ✓ |

Figure 2. a A 3D model of the simulated room

Figure 2. b Photograph of the measured room "Room_0" at Treble Headquarters.
3. Datasets
A. Overview of the Datasets
The challenge presupposes that Treble Technologies’ room simulation software accurately models room acoustics, as evidenced by multiple prior validation studies [14]. Thus, instead of collecting data from real-world rooms, we simulate ten rooms with varying room shapes, furniture layouts, and wall absorption characteristics using Treble Technologies’ simulation software. We use the Treble SDK, a Python interface to the wave-based solver, thus enabling the efficient setup and simulation of large RIR datasets. The wave-based solver uses the Discontinuous Galerkin (DG) method [15], [16]. Although the Treble software also allows for a hybrid combination with a Geometrical Acoustics solver, the datasets of this challenge were simulated purely with a wave-based solver to ensure the best accuracy. The largest simulated frequency was 7 kHz.
Simulated RIRs:
The RIR dataset consists of 3085 simulated monaural and 8th order Ambisonics spatial RIRs at a 32 kHz sampling rate with labeled source-receiver positions. This simulated dataset consists of ten rooms that contain furniture and have assigned surface materials. RIRs are simulated for five source locations and many microphone positions in a grid with 0.5m spacing at 1.5m elevation. Any microphones colliding with room or furniture geometry are omitted. The room dimensions range from 1.75m to 6.3m, and the number of microphones per room ranges from 14 to 137.
| Scenario | Enrollment Data | Test Locations | ||
|---|---|---|---|---|
| Description | Rooms | # RIRs | Rooms | # RIRs |
| Scenario 1 | Room_1 | 5 | Room_1 | 5 |
| Room_3 | 5 | Room_3 | 5 | |
| Room_5 | 5 | Room_5 | 5 | |
| Room_7 | 5 | Room_7 | 5 | |
| Room_9 | 5 | Room_9 | 5 | |
| Total | 25 | 25 | ||
| Scenario 2 | Room_2 | 3 | Room_2 | 5 |
| Room_4 | 3 | Room_4 | 5 | |
| Room_6 | 3 | Room_6 | 5 | |
| Room_8 | 3 | Room_8 | 5 | |
| Room_10 | 3 | Room_10 | 5 | |
| Total | 15 | 25 |
*Table 2: Overview of the Scenarios, Enrollment Data, and Test Locations' For each scenario (see Sec. V-B for descriptions), participants are given n enrollment RIRs from five rooms and must estimate m distances from hidden speaker location utterances in the SDE task.
Control Room:
The organizers also provide a control set of real-world room recordings and their counterpart simulations (‘Room_0’ in Table 1 & Fig. 2b). The measured room, a real physical room in Treble’s headquarters, contains a complicated furniture layout and wall absorption panels. Two loudspeaker positions and ten mic positions are recorded, yielding 20 RIRs with labeled source-receiver positions. The simulation replicates the real room, ‘Room_0’, using the same simulation software, while additionally simulating a 0.5m grid of RIRs. This paired data is provided for participants to calibrate their models, which could be biased toward the different datasets they were trained on.
B. Enrollment Dataset
The organizers withhold a majority of the simulated data from participants, as this challenge asks participants to generate RIRs from limited room information. The goal is to replicate two real-world user scenarios where only sparse room measurements are available, from which participants of this challenge must generate unseen source-receiver position RIRs. Detailed descriptions of the two scenarios are presented in Sec. V-B. The scenarios, enrollment data, and requested distance estimations of test speech are summarized in Table II.
The enrollment data, representing a realistic sparse subset of the overall dataset, are provided. The monoaural RIRs, 8th order Ambisonics RIRs, and source and receiver positions in the room are included. The 3D models for these rooms are also provided and can be used in place of or in addition to the enrollment RIRs to encourage participation from participants who work on applications where the 3D room geometry is obtainable. Although the simulations incorporated material properties, this information is not disclosed to the participants. Instead, the 3D geometry is organized into layers with semantic labels (e.g., “window", “interior wall", “chair," etc.).
4. Evaluation of the Participating Systems and Downstream Task
Participants are asked to generate RIRs at several pre-defined source-receiver locations for each of the rooms to directly evaluate their RIR generation system. Participants’ generated RIRs will be evaluated against the hidden set of Treble-simulated RIRs on the following commonly used metrics:
T20 Mean Percentage Absolute Error:
Reverberation time (T20) is the time it takes for energy in a room to decay 60 dB, obtained from the 20dB evaluation range, as calculated in [17]. Reverberation time is a key RIR metric and characterizes the perceived reverberance of a space. The T20 mean percentage absolute error (MAPE) is defined as follows:
where and are the -th ground-truth T20 value and that of the predicted RIR’s, respectively. Participants will be evaluated on the broadband T20 MPAE and octave-band T20 MPAEs with center frequencies = 4000.
EDF Mean Squared Error:
The energy decay relief (EDF) is the set of spectral decay signatures calculated by Schroeder’s backward integration method [18]. Participants will be evaluated on the mean squared error (MSE) of the broadband and octave-band EDFs. This spectral decay signature offers more fine-grained information than the T20.
The broadband EDF MSE is:
The octave-band EDF MSE is:
where is the energy decay function of octave band of RIR .
DRR Mean Squared Error:
Direct-to-reverberant ratio (DRR) is the ratio in dB between the direct sound energy and the rest of the RIR, as calculated in [17]. The DRR MSE is:
We demonstrate that the Treble simulator generates highly accurate RIRs and that the simulated dataset is legitimate. To establish a performance upper bound, we evaluated the simulated RIRs in the control room ‘Room_0’ against the corresponding measured RIRs provided by Treble Technologies.
The results are shown in Table 3. We set Treble’s wave-based simulations as the upper bound of the performance of generative RIR systems. Furthermore, since the simulated dataset was generated using ground-truth material properties of the real room, it should achieve higher accuracy than participants who are not provided with the material data.
5. Speaker Distance Estimation Downstream Task
A. Overview of the SDE Task
Beyond the typical evaluation metrics listed in Sec. IV, which are primarily related to the perceptual qualities of RIRs, it is important that a generative AI system generates good-quality data in the context of a downstream task. Ideally, a successful generative AI system could recover RIRs of the room with near-perfect precision. By indirectly measuring the quality of the RIRs in the context of the downstream task, it is expected that the generative models can focus more on the properties that are important for the task’s specificity.
To that end, we implement a learning-based speaker distance estimation (SDE) system based on a state-of-the-art open-source model [19] to test the quality of RIRs generated directly for the SDE task. SDE is chosen because it is a task that requires the RIRs to be more physically accurate.
| τ̄20 T20 MAPE [%] | ω̄ EDF MSE [dB] | ρ̄ DRR MSE [dB] | |||||||||||||
| Full | 125 | 250 | 500 | 1k | 2k | 4k | Full | 125 | 250 | 500 | 1k | 2k | 4k | ||
| Treble Simulation | 13.5 | 10.0 | 14.9 | 10.9 | 12.1 | 6.9 | 17.8 | 28 | 17 | 2.8 | 8.4 | 23 | 101 | 100 | 13.3 |
Table 3: Quantitative Error of the Treble Simulated vs. Measured Room. Broadband and octave-band T20 MPAE and EDF MSE, and DRR MSE of the simulated RIRs compared to the measured RIRs in Treble’s room. The low errors show that our simulated dataset using Treble’s software closely matches real-world data.
| Scenario | Model | MAE [m] | MPAE [%] | MAE [m] | MPAE [%] | MAE [m] | MPAE [%] | MAE [m] | MPAE [%] |
|---|---|---|---|---|---|---|---|---|---|
| Scenario 1 | SDE_Treble_scenario_1 | 0.126 | 5.3% | 0.126 | 8.5% | 0.101 | 3.9% | 0.139 | 2.7% |
| SDE_C4DM (Baseline) | 1.37 | 76% | 2.38 | 158% | 1.14 | 45% | 0.479 | 9.4% | |
| Scenario 2 | SDE_Treble_scenario_2 | 0.098 | 7.2% | 0.083 | 9.1% | 0.121 | 4.3% | N/A | N/A |
| SDE_C4DM (Baseline) | 2.73 | 289% | 3.67 | 446% | 1.32 | 52% | N/A | N/A |
Table 4: Speaker Distance Estimation Error - SDE system trained on Treble simulated RIRs versus the C4DM dataset shows that the Treble-trained systems perform much better on the Treble reverberant speech test set than the baseline systems which only saw C4DM RIRs.
B. SDE Test Scenarios and Dataset Configuration
The challenge organizers define two test sets and their corresponding enrollment signals for effective evaluation of the participating generative RIR systems (ref. Table 2).
Scenario 1 – Center-to-Corner Augmentation
Five rooms are chosen to represent the case when the enrollment signals are of five sources recorded by a mic at the center location of the room. For each room in Scenario 1, the five enrollment RIRs are given.
Participants are asked to generate as many RIRs as they need for their SDE model. Then, they are required to use the provided baseline model architecture to develop their own SDE model, e.g., by fine-tuning the baseline model the organizers provide.
Finally, participants are asked to estimate the distance to the five unseen speaker positions in each room, where four different speakers share each location. This results in:
[5 rooms] × [5 positions] × [4 speakers] = 100 reverberant speech test signals.
Scenario 2 – Corner-to-Corner Augmentation
The other five rooms are for the case when the enrollment RIRs are recorded from only three pairs of source-receiver positions, close to the corners of the room. The rest of the process is the same, but for this case, the RIR generation is challenged in a different way as it is exposed only to partial information from a handful of corner positions.
Bonus Track – SDE on Hidden Distance Reverberant Speech
Lastly, in the bonus track, participants are allowed to develop a new model architecture different from the provided anchor baseline, while still addressing both scenarios mentioned above.
C. The Baseline SDE Systems and Their Performance
The challenge organizers develop a baseline system and two oracle systems for participants to gauge the lower and upper bounds, respectively, of SDE systems they develop. To this end, as a lower-bound baseline, the challenge organizers first adopt the state-of-the-art SDE system provided by the authors of [19].
This SDE system is a convolutional recurrent neural network with an attention module. It consists of attention masks that prioritize sections of the input recording, convolutional layers, followed by gated recurrent units (GRUs). The model’s input is a spectrogram {fft_len = 1024, hop_size = 512} of 10 seconds, 32 kHz reverberant speech, and the output is a distance in meters.
The baseline model is trained on reverberant speech constructed from measured RIRs from the C4DM [20] dataset and the VCTK-Corpus speech dataset [21]. It has not seen the particular rooms the challenge introduces, and this is the baseline model that will be provided to participants.
As for the oracle case, the organizers train two SDE models from scratch using the challenge dataset. In doing so, the combined training and validation set of the oracle models consists of all the RIRs except for the ones used for the test sets, thus ensuring the training process utilizes most of the information available in the dataset. Since this amount of information is hard to acquire in practice, we can consider it as oracle performance.
The final train-valid-test split of the challenge dataset is {2,754, 306, 25} for both scenarios 1 and 2. During each training epoch, each RIR is convolved with a randomly sampled speech recording from a training set of VCTK speakers. The test set consists of 25 RIRs convolved with four randomly sampled speech recordings from a test set of VCTK speakers, totaling 100 reverberant speech utterances.
Following the hyperparameters provided in [19], the model is trained for 50 epochs with a batch size of 16 and an initial learning rate of 0.001. The training took approximately fifteen minutes on two NVIDIA A1000 GPUs.
The evaluation metric of the SDE system is the distance MAE across the test dataset and the distance MPAE, which is the distance error as a percentage of the ground truth distance. The results are shown in Tab. IV.
The oracle SDE systems trained on scenario 1 and scenario 2 perform very well, achieving on average:
- 12.6 cm MAE and 5.3% MPAE in Scenario 1.
- 9.8 cm MAE and 7.2% MPAE in Scenario 2.
When evaluating the test set on the baseline model trained only on the C4DM data, we see the error increase to:
- 1.37m MAE and 76% MPAE in Scenario 1.
- 2.73m MAE and 289% MPAE in Scenario 2.
This is because the test set skews toward short distances and falls out of the C4DM distance distribution, which consists of measurements from three very large spaces.
5. Conclusion
In this paper, we propose a room acoustics generative AI challenge that rethinks the potential of generative data augmentation in the domain of spatial audio. First, we recognize the long-standing challenges and work in collecting high-quality and diverse RIRs. Furthermore, we propose the task of augmenting, thereby multiplying, sparse existing acoustic data for fine-tuning speaker distance estimation systems.
The challenge demonstrates how generative models can enhance the generalization capabilities of SDE systems and proposes one conception of a generative AI framework for developing more robust and accurate spatial audio technologies.
This material is in part based on work supported in part by the National Science Foundation under Grant No. 2046963 and 1910940. The authors appreciate Michael Neri at Roma Tre University for the guidance in implementing the baseline distance estimation model.
References
- M. Jeub, M. Schafer, and P. Vary, “A binaural room impulse response database for the evaluation of dereverberation algorithms,” in 2009 16th International Conference on Digital Signal Processing, pp. 1–5, IEEE, 2009.
- J. Eaton, N. D. Gaubitch, A. H. Moore, and P. A. Naylor, “Estimation of room acoustic parameters: The ace challenge,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 10, pp. 1681–1693, 2016.
- J. Traer and J. H. McDermott, “Statistics of natural reverberation enable perceptual separation of sound and space,” Proceedings of the National Academy of Sciences, vol. 113, no. 48, pp. E7856–E7865, 2016.
- C. Chen, U. Jain, C. Schissler, S. V. A. Gari, Z. Al-Halah, V. K. Ithapu, P. Robinson, and K. Grauman, “Soundspaces: Audio-visual navigation in 3d environments,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VI 16, pp. 17–36, Springer, 2020.
- S. Koyama, T. Nishida, K. Kimura, T. Abe, N. Ueno, and J. Brunnström, “Meshrir: A dataset of room impulse responses on meshed grid points for evaluating sound field analysis and synthesis methods,” in 2021 IEEE workshop on applications of signal processing to audio and acoustics (WASPAA), pp. 1–5, IEEE, 2021.
- Z. Tang, R. Aralikatti, A. J. Ratnarajah, and D. Manocha, “Gwa: A large high-quality acoustic dataset for audio processing,” in ACM SIGGRAPH 2022 Conference Proceedings, pp. 1–9, 2022.
- G. Götz, S. J. Schlecht, and V. Pulkki, “A dataset of higher-order ambisonic room impulse responses and 3d models measured in a room with varying furniture,” in 2021 Immersive and 3D Audio: from Architecture to Automotive (I3DA), pp. 1–8, IEEE, 2021.
- A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, et al., “Segment anything,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4015–4026, 2023.
- J. Bao, D. Chen, F. Wen, H. Li, and G. Hua, “CVAE-GAN: Fine-Grained Image Generation through Asymmetric Training,” in IEEE International Conference on Computer Vision (ICCV), pp. 2764–2773, 2017.
- Y. Xu, Y. Shen, J. Zhu, C. Yang, and B. Zhou, “Generative Hierarchical Features from Synthesizing Images,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4430–4430, 2021.
- A. Kuznetsova, A. Sivaraman, and M. Kim, “The potential of neural speech synthesis-based data augmentation for personalized speech enhancement,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5, IEEE, 2023.
- A. Rosenberg, Y. Zhang, B. Ramabhadran, Y. Jia, P. Moreno, Y. Wu, and Z. Wu, “Speech recognition with augmented synthesized speech,” in 2019 IEEE automatic speech recognition and understanding workshop (ASRU), pp. 996–1002, IE