Bulk scene generation
Building scenes one at a time is useful for understanding the components, but for training data you typically need hundreds or thousands of varied scenes. The SceneGenerator automates this by combining a set of rules with an IRCollection to produce randomized scenes at scale.
The process has three parts:
- Define source groups -- each
SourceGroupspecifies aTrackGenerator, how many sources to allocate, which IRs to select from (via Polars filter expressions on the collection), and a priority level for IR allocation - Define listener rules -- device, orientation, and optional device noise
- Generate -- the
SceneGeneratoriterates over receiver positions in the collection and produces as many valid scenes as the IR budget allows
Define scene rules and source groups
SceneRules is the top-level container. Source groups are added to it, each describing a category of sources in the scene.
Each SourceGroup declares:
- which tracks to generate (
TrackGenerator), - candidate IR selection (
source_selectionwith Polars expressions), - source count constraints (
n_sources,min_n_sources), - semantic grouping (
group_tag), - and allocation priority (
priority_on_ir_collection).
Example:
scene_rules = scene.SceneRules(duration_s=20)
conversation = scene.TrackGenerator(
audio_dataset=speech_dataset,
rules=scene.ConversationRules.from_preset(
scene.ConversationRulesPresets.sequential_talkers_increased_overlap,
in_track_level_range_db_spl=(69, 70),
),
talker_identifier="speaker_id",
)
scene_rules.add_source_group(
scene.SourceGroup(
name="conversation",
tracks=conversation,
source_selection=(~pl.col("IS_NOISE_SOURCE")),
n_sources=3,
min_n_sources=3,
group_tag=scene.GroupTag.TARGET,
priority_on_ir_collection=scene.GroupPriority.HIGH,
)
)
Example noise group:
hvac = scene.TrackGenerator(
audio_dataset=hvac_dataset,
rules=scene.NoiseSourceRules(
free_field_level_db_spl=(55, 56),
reuse_single_sample=True,
),
)
scene_rules.add_source_group(
scene.SourceGroup(
name="hvac_noise",
tracks=hvac,
min_n_sources=1,
source_selection=pl.col("IS_NOISE_SOURCE"),
group_tag=scene.GroupTag.BACKGROUND,
priority_on_ir_collection=scene.GroupPriority.MEDIUM,
)
)
Define listener rules
ListenerRules describes how generated scenes should be captured:
- output device,
- orientation or orientation ranges,
- optional device noise/filter specifications.
device_specs = scene.DeviceSpecs(
noise_rules=scene.StaticNoiseRules.from_noise_type_and_level(
noise_type=scene.StaticNoiseType.mems_noise_profile,
level_db_spl=(30, 32),
),
)
device = tsdk.device_library.get_device_by_name("KEMAR051123_1")
scene_rules.set_listener(
scene.ListenerRules(
device=device,
orientation=scene.OrientationRange(
azimuth_range=(-180, 180),
elevation_range=(-10, 10),
roll_range=(0, 0),
),
device_specs=device_specs,
)
)
Generate scenes
The SceneGenerator takes the IR collection and the scene rules, then produces a SceneCollection. It automatically handles receiver selection, source-to-IR assignment (respecting priorities and filter constraints), and track randomization.
The max_n_scenes parameter caps the number of scenes to generate. Each generated scene in the collection can be individually plotted, rendered, or serialized—just like the manually built scene in Scene rendering and targets.
scene_generator = scene.SceneGenerator(
ir_collection=ir_collection,
scene_rules=scene_rules,
data_loader=data_loader # use the data_loader from the IRCollection
)
scene_collection = scene_generator.generate_scenes(max_n_scenes=100)
The result is a SceneCollection that supports indexing, slicing, iteration, and dataframe access:
scene_collection[0].plot()
scene_collection.head(5)
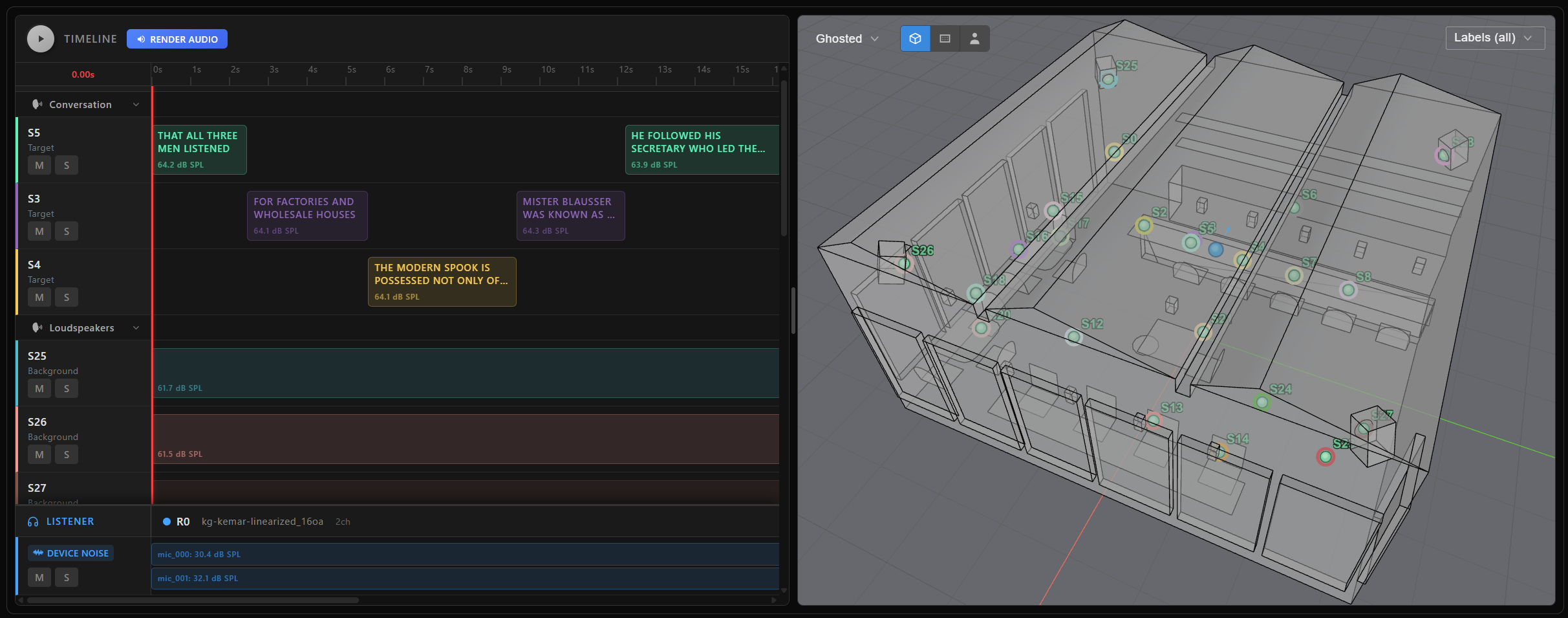
Each item in the collection is a standard AudioScene, so you can:
- render the full mixture,
- render target variants,
- export metadata with
to_struct(), - and extract transcripts.
Make sure you check out the latest features to optimize the workflow with scenes and scene collections from this notebook: