Use case: Audio Scene Generation
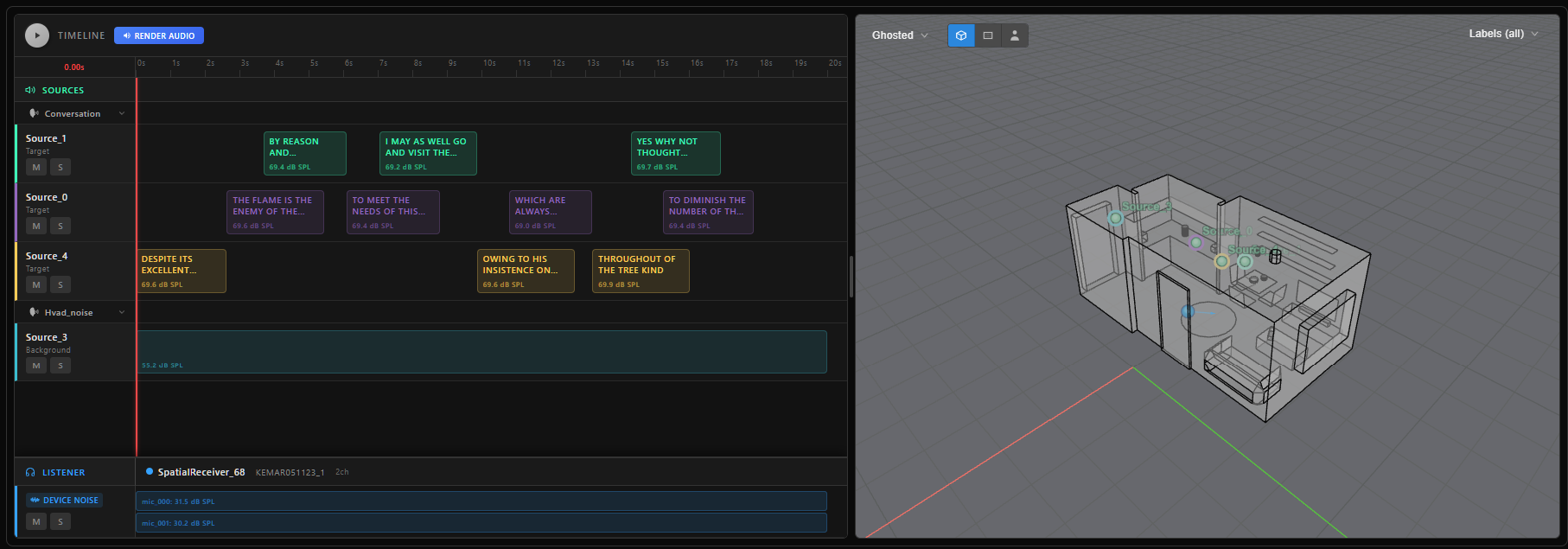
Treble is proud to introduce our new audio scene generation tool. It enables users to create audio scenes with metadata and rule-based conversations featuring speech and noise. The audio scenes can be generated in bulk or as a single scene. A wide range of helper methods automate the process, making it easy to produce highly detailed audio scenes, including speech and noise augmentation, device noise and much more for machine learning, training and testing.
This guide is also available as an interactive Jupyter Notebook. You can view it directly in your browser or download it to run locally.